How to use Google cloud vision optical character recognition(OCR) to detect file content in Laravel
Using Google cloud vision API (Optical Character Recognition feature) to extract and detect text in images and files in a Laravel application


In this article, we'll be looking at how to use the Google cloud vision API optical character recognition(OCR) to detect text in files and images in a Laravel application.
The Vision API can detect and extract text from images. There are two annotation features that support optical character recognition (OCR):
TEXT_DETECTION detects and extracts text from any image. For example, a photograph might contain a street or traffic sign. The JSON includes the entire extracted string, individual words, and their bounding boxes.
DOCUMENT_TEXT_DETECTION also extracts text from an image, but the response is optimized for dense text and documents. The JSON includes page, block, paragraph, word, and break information.
TextAnnotation contains a structured representation of OCR extracted text. The hierarchy of an OCR extracted text structure is like this: TextAnnotation -> Page -> Block -> Paragraph -> Word -> Symbol Each structural component, starting from Page, may further have their own properties. Properties describe detected languages, breaks etc.. Please refer to the TextAnnotation.TextProperty message definition below for more detail.
- Checking the vertex
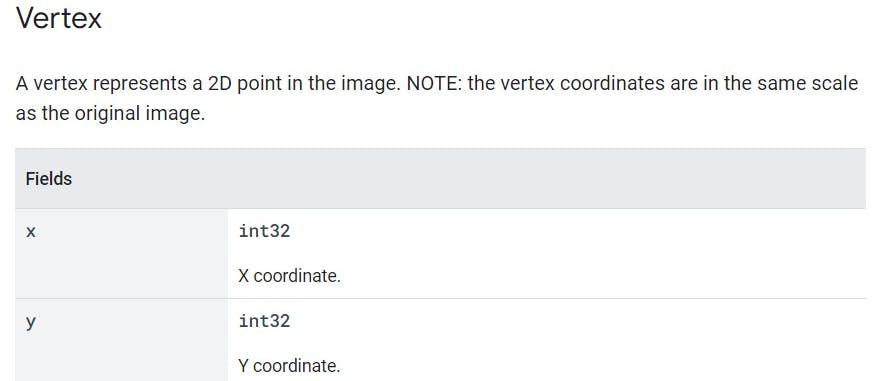
- Text property
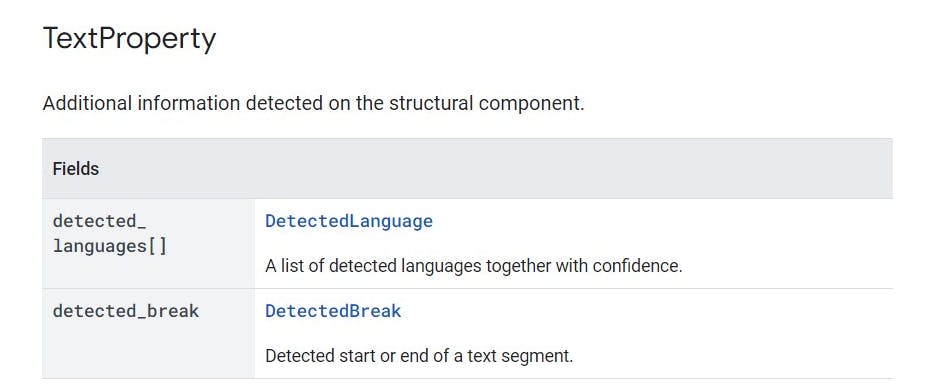
- Break Type

Other features of the TextAnnotation can be found here
In this tutorial How to use Google cloud vision API safe search detection to detect explicit content on image uploads in Laravel, we covered the details on how to create a Google Cloud Platform (GCP) project, service account credentials and cloud vision package integration into Laravel.
In order We'll go straight to exploring how Optical character recognition works on file uploads because we already have a form for uploading files from the previous feature integration.
NB: each feature has its own route in the web.php file for clarity purposes.
You can also check into a specific branch on github to go over its implementation
- Detect text in a local image
The Vision API can perform feature detection on a local image file by sending the contents of the image file as a base64 encoded string in the body of your request.
Here's a repository with an example of its integration.
We can run the detection inside the post method when the file is uploaded.
- Import the classes
use Google\Cloud\Vision\V1\ImageAnnotatorClient;
// this HtmlStringclass is used to format the text detected on the image
use Illuminate\Support\HtmlString;
- Running the textDetection on the uploaded image
public function detectTextInImage(Request $request)
{
$request->validate([
'avatar' => 'required|image|max:10240',
]);
try {
$imageAnnotatorClient = new ImageAnnotatorClient([
//we can also keep the details of the google cloud json file in an env and read it as an object here
'credentials' => config_path('laravel-cloud.json')
]);
# annotate the image
$image = file_get_contents($request->file("avatar"));
//run the textdection feature on the image
$response = $imageAnnotatorClient->textDetection($image);
if ($error = $response->getError()) {
// returns error from annotator client
return redirect()->back()
->with('danger', $error->getMessage());
}
$texts = $response->getTextAnnotations();
//to ascertain the number of texts on the image
$number_of_texts = count($texts);
//text on image saved in to this variable
$image_text_content = '';
foreach ($texts as $text) {
$image_text_content .= $text->getDescription() . PHP_EOL;
//the text description on the image
print($text->getDescription() . PHP_EOL);
# get bounds using the vertex feature
$vertices = $text->getBoundingPoly()->getVertices();
$bounds = [];
foreach ($vertices as $vertex) {
$bounds[] = sprintf('(%d,%d)', $vertex->getX(), $vertex->getY());
}
// to access the bounds of the image
print('Bounds: ' . join(', ', $bounds) . PHP_EOL);
}
return new HtmlString($image_text_content);
return [$image_text_content];
$imageAnnotatorClient->close();
//return home with a success message
return redirect()->route('home')
->with('success', "Text detection successful!!! Number of Texts $number_of_texts and text on image uploaded");
} catch (Exception $e) {
return $e->getMessage();
}
}
- We'll upload this image and see how the Textdection returns the content

- When the HTML string class is not applied to format the text content from the image

- Proper formatting with number of texts and image text displayed.
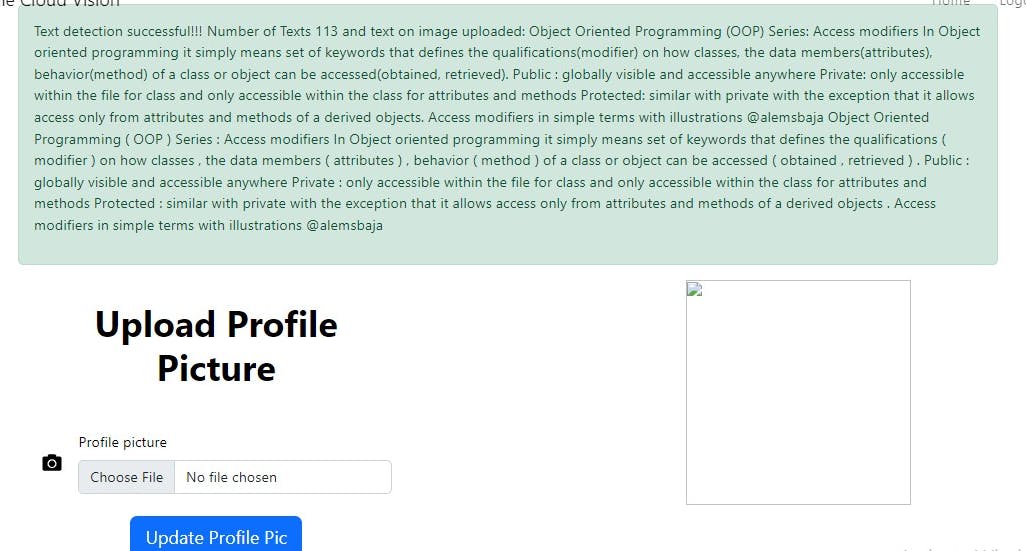
- Detect text in a remote image ( Google cloud storage, Cloudinary, S3 bucket etc)
For your convenience, the Vision API can perform feature detection directly on an image file located in Google Cloud Storage or on the Web without the need to send the contents of the image file in the body of your request.
Caution: When fetching images from HTTP/HTTPS URLs, Google cannot guarantee that the request will be completed. Your request may fail if the specified host denies the request (for example, due to request throttling or DOS prevention), or if Google throttles requests to the site for abuse prevention. You should not depend on externally-hosted images for production applications.
Simply replace the upload file name with the image URL on the internet or remote storage
$image = 'file_path...https://googleapis.com.......png';
//run the textdection feature on the image
$response = $imageAnnotatorClient->textDetection($image);
- DOCUMENT TEXT DETECTION
public function documentTextDetection(Request $request)
{
$request->validate([
'avatar' => 'required|max:10240',
]);
try {
$docAnnotatorClient = new ImageAnnotatorClient([
//we can also keep the details of the google cloud json file in an env and read it as an object here
'credentials' => config_path('laravel-cloud-features.json')
]);
# annotate the image
$doc = file_get_contents($request->file("avatar"));
$response = $docAnnotatorClient->documentTextDetection($doc);
$annotation = $response->getFullTextAnnotation();
//formatted text
$formatted_text = new HtmlString($annotation->getText());
//final unformatted text
$block_text = '';
//bounds
$bounds = [];
# print out detailed and structured information about document text
if ($annotation) {
foreach ($annotation->getPages() as $page) {
foreach ($page->getBlocks() as $block) {
foreach ($block->getParagraphs() as $paragraph) {
foreach ($paragraph->getWords() as $word) {
foreach ($word->getSymbols() as $symbol) {
$block_text .= $symbol->getText();
}
$block_text .= ' ';
}
$block_text .= "\n";
}
// printf('Block content: %s', $block_text);
// printf(
// 'Block confidence: %f' . PHP_EOL,
// $block->getConfidence()
// );
# get bounds
$vertices = $block->getBoundingBox()->getVertices();
foreach ($vertices as $vertex) {
$bounds[] = sprintf(
'(%d,%d)',
$vertex->getX(),
$vertex->getY()
);
}
// print('Bounds: ' . join(', ', $bounds) . PHP_EOL);
// print $block_text;
}
}
$text_bounds = join(', ', $bounds);
return redirect()->route('home')
->with('success', "Text detection successful!!! Formatted Text on image uploaded: $formatted_text, Bounds: $text_bounds");
} else {
//if no text is found in the document
print('No text found' . PHP_EOL);
return redirect()->route('home')
->with('danger', "No text found!!!");
}
//return home with a success message
} catch (Exception $e) {
return $e->getMessage();
}
$docAnnotatorClient->close();
}
- We'll upload this image and see how the Textdection returns the content

- Proper formatting with image text displayed and text bounds.

The Vision API can detect and transcribe text from PDF and TIFF files stored in Cloud Storage.
Document text detection from PDF and TIFF must be requested using the files:asyncBatchAnnotate function, which performs an offline (asynchronous) request and provides its status using the operations resources.
Google vision docs pdf detection
Output from a PDF/TIFF request is written to a JSON file created in the specified Cloud Storage bucket.
- Limitations
The Vision API accepts PDF/TIFF files up to 2000 pages. Larger files will return an error.
- Document text detection requests
Currently PDF/TIFF document detection is only available for files stored in Cloud Storage buckets. Response JSON files are similarly saved to a Cloud Storage bucket.
In this tutorial, How to upload files to Google cloud storage from a Laravel application we looked at how to setup Google cloud storage
public function detectPDFinGCS()
{
//path to pdf file on cloud storage
$path = 'gs://path/to/your/document.pdf';
//path to store the json result on cloud storage
$output = 'gs://path/to/store/results/';
# select ocr feature
$feature = (new Feature())
->setType(Type::DOCUMENT_TEXT_DETECTION);
# set $path (file to OCR) as source
$gcsSource = (new GcsSource())
->setUri($path);
# supported mime_types are: 'application/pdf' and 'image/tiff'
$mimeType = 'application/pdf';
$inputConfig = (new InputConfig())
->setGcsSource($gcsSource)
->setMimeType($mimeType);
# set $output as destination
$gcsDestination = (new GcsDestination())
->setUri($output);
# how many pages should be grouped into each json output file.
$batchSize = 2;
$outputConfig = (new OutputConfig())
->setGcsDestination($gcsDestination)
->setBatchSize($batchSize);
# prepare request using configs set above
$request = (new AsyncAnnotateFileRequest())
->setFeatures([$feature])
->setInputConfig($inputConfig)
->setOutputConfig($outputConfig);
$requests = [$request];
# make request
$imageAnnotator = new ImageAnnotatorClient([
//we can also keep the details of the google cloud json file in an env and read it as an object here
'credentials' => config_path('laravel-cloud-features.json')
]);
$operation = $imageAnnotator->asyncBatchAnnotateFiles($requests);
print('Waiting for operation to finish.' . PHP_EOL);
$operation->pollUntilComplete();
# once the request has completed and the output has been
# written to GCS, we can list all the output files.
preg_match('/^gs:\/\/([a-zA-Z0-9\._\-]+)\/?(\S+)?$/', $output, $match);
$bucketName = $match[1];
$prefix = isset($match[2]) ? $match[2] : '';
$googleConfigFile = file_get_contents(config_path('laravel-cloud-features.json'));
$storage = new StorageClient([
'keyFile' => json_decode($googleConfigFile, true)
]);
$bucket = $storage->bucket($bucketName);
$options = ['prefix' => $prefix];
$objects = $bucket->objects($options);
# save first object for sample below
$objects->next();
$firstObject = $objects->current();
# list objects with the given prefix.
print('Output files:' . PHP_EOL);
foreach ($objects as $object) {
print($object->name() . PHP_EOL);
}
# process the first output file from GCS.
# since we specified batch_size=2, the first response contains
# the first two pages of the input file.
$jsonString = $firstObject->downloadAsString();
$firstBatch = new AnnotateFileResponse();
$firstBatch->mergeFromJsonString($jsonString);
# get annotation and print text
foreach ($firstBatch->getResponses() as $response) {
$annotation = $response->getFullTextAnnotation();
print($annotation->getText());
}
$imageAnnotator->close();
}
Field-specific considerations:
inputConfig - replaces the image field used in other Vision API requests. It contains two child fields: gcsSource.uri - the Google Cloud Storage URI of the PDF or TIFF file (accessible to the user or service account making the request).
mimeType - one of the accepted file types: application/pdf or image/tiff.
outputConfig - specifies output details. It contains two child field:
gcsDestination.uri - a valid Google Cloud Storage URI. The bucket must be writeable by the user or service account making the request. The filename will be output-x-to-y, where x and y represent the PDF/TIFF page numbers included in that output file. If the file exists, its contents will be overwritten.
batchSize - specifies how many pages of output should be included in each output JSON file.
Here's the tutorial repository
Thank you for reading this article!!!.
If you find this article helpful, please share it with your network and feel free to use the comment section for questions, answers, and contributions.